Parents : Problem Solving In Computer Science
Siblings :
| Date and time note was created | $= dv.current().file.ctime |
| Date and time note was modified | $= dv.current().file.mtime |
Data structures are sort of containers to hold data strategically to improve upon the Time Complexity and space complexity of a certain program. It is also clear from name that “data” is raw information and “structures” are containers.
Topics to cover
- Arrays (both multi-dimensional and single dimensional)
- Strings
- Sliding Window
- Stack
- Queue
- Linked List
- Binary Search
- Recursion
- Trees
Two types of data structures exist
Linear Data Structures
Linear data structures are data structures that store data in a linear fashion.
Following are the linear data structures I have read/know about a little right now.
- Arrays
- Linked List
- Stack
- Queues
Arrays
Techniques used repeatedly
Normalise values in range
- Note: Thus to normalise the elements’ index. The number of iterations in the range and to reiterate the array again after going out of array range, we divide it by number of elements in the range.
- `index % n | newIndex % n
Array operations
Rotate an array
- To reiterate the values in an array from the start we mod the index value by n (size of the array)
- To rotate an array we must find the new index where the element from the array would be located or shifted to after k rotations.
Example
For array : [1,2,3,4,5,6,7] and no. of rotations(k) = 3
To find the new index for the value at index ‘i’ we move k positions forward using i + k

But here there are two problems to consider here
- The array would go out of bound when we add the k>n or for the last element when k>0.
- There would be wasteful iterations make when k is a large number.
To go deep into this solution of this problem review the following:
Lets do the number of rotations upto number of elements in the range of the array i.e 0<=k<=n
For k=0 , [1,2,3,4,5,6,7] , No change
For k=1 , [7,1,2,3,4,5,6] , 1 element shifts in front
For k=2 , [6,7,1,2,3,4,5] , 2 elements shift in front
For k=3 , [5,6,7,1,2,3,4] , 3 elements shift in front
For k=4 , [4,5,6,7,1,2,3] , 4 elements shift in front
For k=5 , [3,4,5,6,7,1,2] , 5 elements shift in front
For k=6 , [2,3,4,5,6,7,1] , 6 elements shift in front
For k=7 , [1,2,3,4,5,6,7] , No change as all the elements reset
back to original position
…
…
…
For k=108 [5,6,7,1,2,3,4] (found by the following approach not that I am sitting and doing 108 rotations by hand duh!!💁♂️)
As we can see the range after the k>=n starts repeating itself thus we can normalise values in range of arrays,if k>=n by finding the remainder left after dividing the range by n (as it will give the net rotations to be made)
For instance, k=108 becomes k=108 % n = 108 % 7 =3 (net rotations)
Also when in case of i=7 the number goes out of range of array and new index is to be calculated,
We find (i+k) ⇒ modulus it by n i.e (i+k)%n ⇒ new index =(7+3) % k=10 % 7= 3.
Merge two sorted arrays
Approach One
Time Complexity: O(n) Space Complexity: O(n)
Requirements: Two sorted arrays, a result (merged) array.
Algorithm
- Two sorted arrays are traversed using two pointers.
- While traversing the pointer to one array is checked with the other array pointer and whichever is smaller is pushed to merged array and the pointer also moves forward.
- After one traversal,any remaining array’s elements are pushed to the merged array.
Pseudo code for merge function
void merge(vector<int>arr,int low,int mid,int high){
}Concatenation in arrays
If elements are to be added/appended to the end of the same array use following methods
- use loop and insert elements using traversal by i+n operation onto new array of desired size (most optimised )
- using Insert function in vectors
- using push_back on the input array
Counting Elements in Array
The approaches to count elements in an array are as follows
- Brute force counting using 2 loops
- Brute forces counting by sorting the array first and then calculating the count
- Counting the elements simulating hash map mechanism using array when range is defined todo
- Counting the elements using Hash map data structure
Brute force counting using 2 loops
vector<pair<int, int>> countArrayUsingLoops(vector<int> &nums)
{
vector<int> seen;
int n = nums.size();
int count = 1;
vector<pair<int, int>> res;
for (int i = 0; i < n; i++)
{
count = 1;
if (find(seen.begin(), seen.end(), nums[i]) == seen.end())
{
for (int j = i + 1; j < n; j++)
{
if (nums[i] == nums[j])
{
count++;
seen.push_back(nums[i]); // The element is now marked as seen or visited.
}
}
res.push_back({nums[i], count});
}
//! This should be avoided as range based for loop iterates over the vector and making operations
//! over it can cause iterators to become undefined returning ambiguous results. Instead use another vector for checking seen values.
// for (auto &it : res)
// {
// if (it.first != nums[i])
// {
// res.push_back({nums[i], count});
// }
// }
}
return res;
}
Brute forces counting by sorting the array first and then calculating the count
vector<pair<int, int>> countArrayUsingSorting(vector<int> &nums)
{
int n = nums.size(); // Size of the array
sort(nums.begin(), nums.end()); // REQUIRED
vector<pair<int, int>> countArray;
int count = 1;
for (int i = 0; i < n; i++)
{
if (i < n - 1)
{
if (nums[i] == nums[i + 1])
{
count++;
}
else
{
countArray.push_back({nums[i], count});
count = 1;
}
}
else
{
countArray.push_back({nums[i], count});
}
}
for (auto &it : countArray)
{
cout << it.first << " " << it.second << endl;
}
return countArray;
}Counting the elements using Hash map data structure
vector<pair<int, int>> countArrayUsingHashMap(vector<int> &nums)
{
unordered_map<int, int> countMap;
for (auto &it : nums)
countMap[it]++; // Store the counts and increase if the value is found again i.e according to its frequency
vector<pair<int, int>> res;
for (auto &it : countMap)
res.push_back(it);
return res;
}
Linked List
Reverse a Linked List
To reverse a linked list we need to use three nodes
- Dummy node for taking in account new head node
- Next node of the current head node to remember the next node after link to it is broken from the actual head node
- Current head for traversing the linked list.
Reverse A Linked List.excalidraw
⚠ Switch to EXCALIDRAW VIEW in the MORE OPTIONS menu of this document. ⚠ You can decompress Drawing data with the command palette: ‘Decompress current Excalidraw file’. For more info check in plugin settings under ‘Saving’
Excalidraw Data
Text Elements
Link to original
Non-linear Data Structures
Non-Linear data structures are data structures that store data in a Non-linear fashion.
Following are the non-linear data structures I have read/know about a little right now.
- Trees
- Graphs
Trees
Trees fall under the of Non-linear Data Structures as tree store Natural Hierarchical data.
Hierarchical data is a type of data :
- contains levels
- levels branch from another levels
- data is arranged accordingly from high to low.
In real world data which grows eventually and enormously for which insertion and searching must be done more efficiently.Trees is a very useful data structure in such cases.
Example:
In a company the employees are stored in a natural hierarchical data format as depicted by following diagram.

Advantages of trees over other data structures:
1. Searching
Searching is faster than Linear Data Structures as the search space is reduced to a certain area.
2. Insertion
No upper limit to store data i.e a new node can be inserted at any point of time in trees while in arrays the size of data is fixed.
Tree Terminology
- Node
- root
- parent
- leaf node
- internal nodes
- ancestors
- descendants
- common ancestor
- cousins
- grandparent
Depth of a node “x”
- Length of path from root to that node (x)
- No. of edges from root to that node.
Height of a node “x”
- No of edges in longest path from x to leaf
Height of tree
Height of tree= height of root node = max depth of the tree
Tree is a recursive data structure meaning: In Trees most operations use recursive functions as each portion of a tree is a tree in itself. Trees has a root and sub-trees
to avoid confusion between terminologies: 1. Height: Imagine measuring a person’s height, we do it from toe to head (leaf to root). 2. Depth: Imagine measuring depth of a sea, we do it from earth’s surface to ocean bed (root to leaf).
Other facts
If there are n nodes then there must be n-1 edges present this is so because the root node doesn’t consist of the edge
Binary Tree Construction
To construct a binary tree when two traversal orders are given
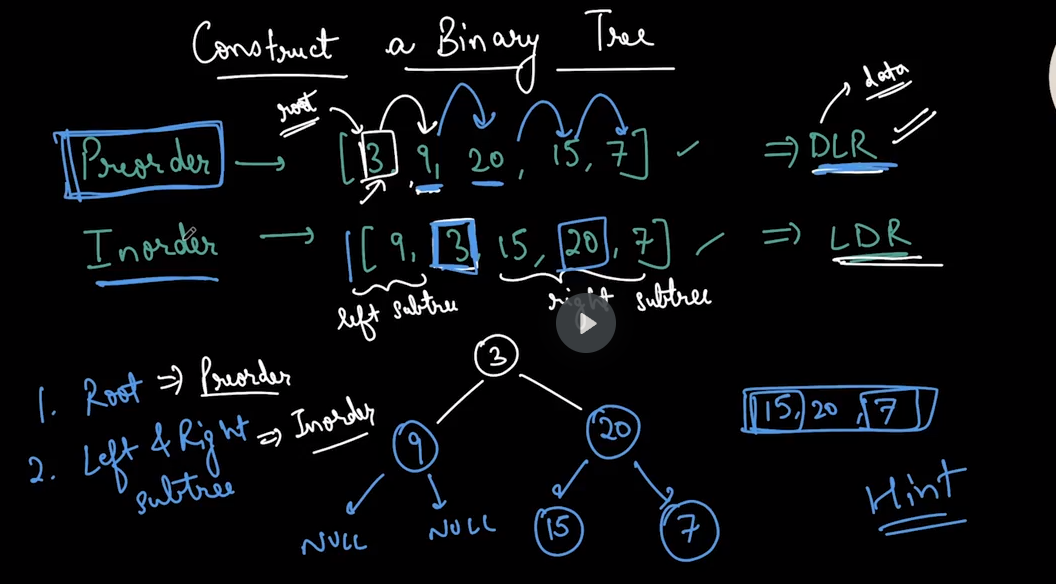
- For construction of any binary tree we need two things
- root node
- left and right sub-tree
- Hence in each question two orders would be given
- one for retrieving the root node
- another for retrieving the left and right sub-tree
Construct binary tree from in-order and pre-order
When in-order and post-order traversal is given - Take the root node from the post-order from ending. - Take the left and right sub-tree from starting.
Code
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode * makeTree(vector < int > & inorder, vector < int > & postorder, int start, int end, int & rootIndex, unordered_map < int, int > & umap) {
if (rootIndex < 0) {
return NULL;
}
if (start > end) {
return NULL;
}
int rootVal;
rootVal = postorder[rootIndex];
rootIndex--;
int inorderIndex = umap[rootVal];
TreeNode * newNode = new TreeNode(rootVal);
// here the order of the statements matter too they should be according to the
// traversal i.e here post order is taken in reverse which is DRL so the right
// should be considered first before left.
newNode -> right = makeTree(inorder, postorder, inorderIndex + 1, end, rootIndex, umap);
newNode -> left = makeTree(inorder, postorder, start, inorderIndex - 1, rootIndex, umap);
return newNode;
}
TreeNode * buildTree(vector < int > & inorder, vector < int > & postorder) {
// number of nodes in the tree
int n = inorder.size();
if (n == 0) {
return NULL;
}
int rootIndex = n - 1;
// for storing the positions in the umap
unordered_map < int, int > umap;
for (int i = 0; i < n; i++)
umap[inorder[i]] = i;
// for(auto&it:umap)
// cout<<it.first<<" "<<it.second<<endl;
return makeTree(inorder, postorder, 0, n - 1, rootIndex, umap);
}
};
Time Complexity: O(N) as the recursion takes O(n) Space Complexity: O(2xN) as the stack uses N nodes at max and hashmap is used for storing indexes
- Alternative approach includes without use of hashmap for searching then the time complexity turns to O(N^2)
Construct binary tree from pre-order and in-order traversal
When in-order and pre-order traversal is given - Take the root node from the pre-order from starting. - Take the left and right sub-tree from starting.
Code
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
// calculate the root element in the inorder array for calculating the left and right subtrees' ranges
int findIndexInorder(vector<int>inorder,int rootVal){
// use the find function to find the value in vector and subtract the begin index to get the value in integer
return (find(inorder.begin(),inorder.end(),rootVal)-inorder.begin());
}
// as in this ques we need to create different left and right subtree
// its easier to create a separate function "makeTree"
TreeNode* makeTree(vector<int>& preorder, vector<int>& inorder,int start,int end,int & rootIndex){
// function contains 4 parameters
// preorder: array from which we will take the root node
// inorder : array from which we will calculate the left and right subtrees
// start : variable to store the start of the subtree
// end : variable to store the end of the subtree
// rootIndex : stores the root index
if(start>end){
return NULL;// Base condition
}
int rootVal=preorder[rootIndex];
rootIndex++;
TreeNode* newNode=new TreeNode(rootVal);
// calculate the element in the inorder array for calculating the left and right subtrees' ranges
int inorderIndex=findIndexInorder(inorder,rootVal);
newNode->left=makeTree(preorder,inorder,start,inorderIndex-1,rootIndex);
newNode->right=makeTree(preorder,inorder,inorderIndex+1,end,rootIndex);
return newNode;
}
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
// size for traversing and creation of the tree
int n=preorder.size();
if(n==0){
return NULL;
}
int rootIndex=0;
// in this method we take the pointers to left and right for constructing the left and right subtrees ranges.
return makeTree(preorder,inorder,0,n-1,rootIndex);
}
};
Time Complexity: O(N^2) as the recursion takes O(n) and findIndex() too takes O(n) Space Complexity: O(N) as the stack uses N nodes at max
- Alternative approach includes to use hashmap for searching then the time complexity turns to O(N)
Tree Traversals
4 methods traversal
- Inorder - LDR (left,data,right)
- Preorder - DLR
- Postorder - LRD
- Level order
- morris traversal
Inorder traversal
LDR is performed from the root node Example: First the left subtree of a node is taken care of and then the root data of that subtree is printed then right subtree is taken of repeat(recursion) until end of the tree is reached
- Revise recursion before reading the following code
void inorder(root){
if(root==NULL)
return;
inorder(root->left);
cout<<root->val;
inorder(root->left);
}
void preorder(root){
if(root==NULL)
return;
cout<<root->val;
preorder(root->left);
preorder(root->left);
}
}
void postorder(root){
if(root==NULL)
return;
postorder(root->left);
postorder(root->left);
cout<<root->val;
}